My contributions to CPython during 2016 Q4 (october, november, december):
hg log -r 'date("2016-10-01"):date("2016-12-31")' --no-merges -u Stinner
Statistics: 105 non-merge commits + 31 merge commits (total: 136 commits).
Previous report: My contributions to CPython during 2016 Q3. Next report: My contributions to CPython during 2017 Q1.
Table of Contents:
- Python startup performance regression
- Optimizations
- Code placement and __attribute__((hot))
- Interesting bug: duplicated filters when tests reload the warnings module
- Contributions
- regrtest
- Other changes
Python startup performance regression
Regresion
My work on tracking Python performances started to become useful :-) I identified a performance slowdown on the bm_python_startup benchmark (average time to start Python).
Before September 2016, the start took around 17.9 ms. At September 15, after the CPython sprint, it was better: 13.4 ms. But suddenly, at september 19, it became much worse: 22.8 ms. What happened?
Timeline of Python startup performance on speed.python.org:
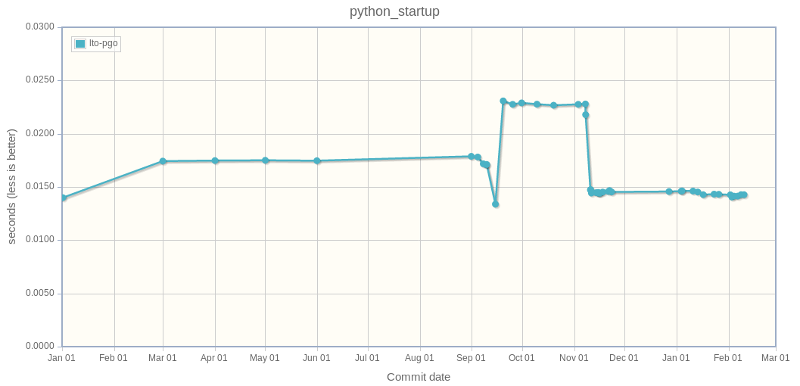
I looked at commits between September 15 and September 19, and I quickly identified the commit of the convert re flags to (much friendlier) IntFlag constants (issue #28082). The re module now imports the enum module to get a better representation for their flags. Example:
$ ./python Python 3.7.0a0 >>> import re; re.M <RegexFlag.MULTILINE: 8>
Revert
At November 7, I opened the issue #28637 to propose to revert the commit to get back better Python startup performance. The revert was approved by Guido van Rossum, so I pushed it.
Better fix
I also noticed that the re module is not imported by default if Python is installed or if Python is run from its source code directory. The re module is only imported by default if Python is installed in a virtual environment.
Serhiy Storchaka proposed a change to not import re anymore in the site module when Python runs into a virutal environment. Since the benefit was obvious (avoid an import at startup) and simple, it was quickly merged.
Restore reverted enum change
Since using enum in re has no more impact on Python startup performance by default, the enum change was restored at November 14.
Sadly, the enum change still have an impact on performance: re.compile() became 1.2x slower (312 ms => 376 ms: +20%).
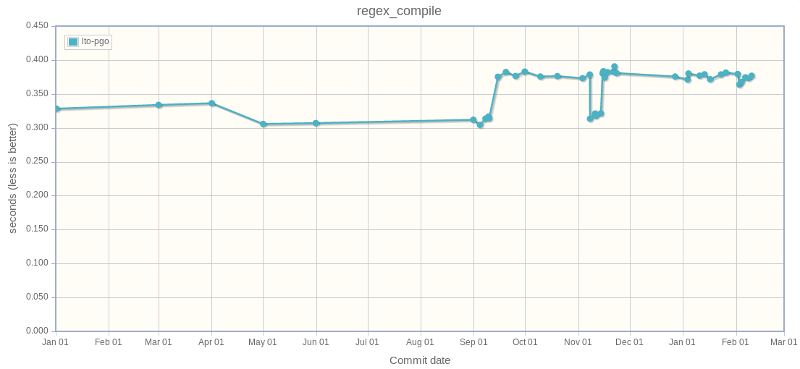
I think that it's ok since it is very easy to use precompiled regular expressions in an application: store and reuse the result of re.compile(), instead of calling directly re.match() for example.
Optimizations
FASTCALL
Same than 2016 Q3: I pushed a lot of changes for FASTCALL optimizations, but I will write a dedicated article later.
No int+int micro-optimization, thank you
After 2 years of benchmarking and a huge effort of making Python benchmarks more reliable and stable, I decided to close the issue #21955 "ceval.c: implement fast path for integers with a single digit" as REJECTED. It became clear to me that such micro-optimization has no effect on non-trivial code, but only on specially crafted micro-benchmarks. I added a comment in the C code to prevent further optimizations attempts:
/* NOTE(haypo): Please don't try to micro-optimize int+int on CPython using bytecode, it is simply worthless. See http://bugs.python.org/issue21955 and http://bugs.python.org/issue10044 for the discussion. In short, no patch shown any impact on a realistic benchmark, only a minor speedup on microbenchmarks. */
timeit
I enhanced the timeit benchmark module to make it more reliable (issue #28240):
- Autorange now starts with a single loop iteration instead of 10. For example, python3 -m timeit -s 'import time' 'time.sleep(1)' now only takes 4 seconds instead of 40 seconds.
- Repeat the benchmarks 5 times by default, instead of only 3, to make benchmarks more reliable.
- Remove -c/--clock and -t/--time command line options which were deprecated since Python 3.3.
- Add nsec (nanosecond) unit to format timings
- Enhance formatting of raw timings in verbose mode. Add newlines to the output for readability.
Micro-optimizations
I also pushed two minor micro-optimizations:
- Use PyThreadState_GET() macro in performance critical code. _PyThreadState_UncheckedGet() calls are not inlined as expected, even when using gcc -O3.
- Modify type_setattro() to call directly _PyObject_GenericSetAttrWithDict() instead of PyObject_GenericSetAttr(). PyObject_GenericSetAttr() is a thin wrapper to _PyObject_GenericSetAttrWithDict().
Code placement and __attribute__((hot))
On speed.python.org, I still noticed random performance slowdowns on the evil call_simple benchmark. This benchmark is a micro-benchmark measuring the performance of a single Python function call, it is CPU-bound and very small and so impact by CPU caches. I was bitten again by significant performance slowdown only caused by code placement.
It wasn't possible to use Profiled Guided Optimization (PGO) on the benchmark runner, since it used Ubuntu 14.04 and GCC crashed with an "internal error".
So I tried something different: mark "hot functions" with __attribute__((hot)). It's a GCC and Clang attribute helping code placements: "hot functions" are moved to a dedicated ELF section and so are closer in memory, and the compiler tries to optimize these functions even more.
The following functions are considered as hot according to statistics collected by Linux perf record and perf report commands:
- _PyEval_EvalFrameDefault()
- call_function()
- _PyFunction_FastCall()
- PyFrame_New()
- frame_dealloc()
- PyErr_Occurred()
I added a _Py_HOT_FUNCTION macro which uses __attribute__((hot)) and used _Py_HOT_FUNCTION on these functions (issue #28618).
Read also my previous blog article Analysis of a Python performance issue for a deeper analysis.
Sadly, after I wrote this blog post and after more analysis of call_simple benchmark results, I saw that __attribute__((hot)) wasn't enough. I still had random major performance slowdown.
I dediced to upgrade the performance runner to Ubuntu 16.04. It was dangerous because nobody has access to the physical server, so it may takes weeks to repair it if I did a mistake. Hopefully, the upgrade gone smoothly and I was able to run again all benchmarks using PGO. As expected, using PGO+LTO, benchmark results are more stable!
Interesting bug: duplicated filters when tests reload the warnings module
Python test suite has an old bug: the issue #18383 opened in July 2013. Sometimes, the test suite emits the following warning:
[247/375] test_warnings Warning -- warnings.filters was modified by test_warnings
Since it's only a warning and it only occurs in the Python test suite, it was a low priority and took 3 years to be fixed! It also took time to find the right design to fix the root cause.
Duplicated filters
test_warnings imports the warnings module 3 times:
import warnings as original_warnings # Python
py_warnings = support.import_fresh_module('warnings', blocked=['_warnings']) # Python
c_warnings = support.import_fresh_module('warnings', fresh=['_warnings']) # C
The Python warnings module (Lib/warnings.py) installs warning filters when the module is loaded:
_processoptions(sys.warnoptions)
where sys.warnoptions contains the value of the -W command line option.
If the Python module is loaded more than once, filters are duplicated.
First fix: use the right module
I pushed a first fix in september 2015.
Fix test_warnings: don't modify warnings.filters. BaseTest now ensures that unittest.TestCase.assertWarns() uses the same warnings module than warnings.catch_warnings(). Otherwise, warnings.catch_warnings() will be unable to remove the added filter.
Second fix: don't add duplicated filters
Issue #18383: the first patch was proposed by Florent Xicluna in 2013: save the length of filters, and remove newly added filters after warnings modules are reloaded by test_warnings. December 2014, Serhiy Storchaka reviewed the patch: he didn't like this workaround, he would like to fix the root cause.
March 2015, Alex Shkop proposed a patch which avoids to add duplicated filters.
September 2015, Martin Panter proposed to try to save/restore filters on the C warnings module. I proposed something similar in the issue #26742. But this solution has the same flaw that Florent's idea: it's only a workaround.
Martin also proposed add a private flag to say that filters were already set to not try to add again same filters.
Finally, in may 2016, Martin updated Alex's patch avoiding duplicated filters and pushed it.
Third fix
The filter comparisons wasn't perfect. A filter can be made of a precompiled regular expression, whereas these objects don't implement comparison.
November 2016, I opened the issue #28727 to propose to implement rich comparison for _sre.SRE_Pattern.
My first patch didn't implement hash() and had different bugs. It took me almost one week and 6 versions to write complete unit tests and handle all cases: support bytes and Unicode and handle regular expression flags.
Serhiy Storchaka found bugs and helps me to write the implementation.
Contributions
As usual, I reviewed and pushed changes written by other contributors:
Issue #27896: Allow passing sphinx options to Doc/Makefile. Patch written by Julien Palard.
Issue #28476: Reuse math.factorial() in test_random. Patch written by Francisco Couzo.
Issue #28479: Fix reST syntax in windows.rst. Patch written by Julien Palard.
Issue #26273: Add new constants: socket.TCP_CONGESTION (Linux 2.6.13) and socket.TCP_USER_TIMEOUT (Linux 2.6.37). Patch written by Omar Sandoval.
Issue #28979: Fix What's New in Python 3.6: compact dict is not faster, but only more compact. Patch written by Brendan Donegan.
Issue #28147: Fix a memory leak in split-table dictionaries: setattr() must not convert combined table into split table. Patch written by INADA Naoki.
Issue #29109: Enhance tracemalloc documentation:
- Wrong parameter name, 'group_by' instead of 'key_type'
- Don't round up numbers when explaining the examples. If they exactly match what can be read in the script output, it is to easier to understand (4.8 MiB vs 4855 KiB)
- Fix incorrect method link that was pointing to another module
Patch written by Loic Pefferkorn.
regrtest
- regrtest --fromfile now accepts a list of filenames, not only a list of test names.
- Issue #28409: regrtest: fix the parser of command line arguments.
Other changes
- Fix _Py_normalize_encoding() function: It was not exactly the same than Python encodings.normalize_encoding(): the C function now also converts to lowercase.
- Issue #28256: Cleanup _math.c: only define fallback implementations when needed. It avoids producing deadcode when the system provides required math functions, and so enhance the code coverage.
- _csv: use _PyLong_AsInt() to simplify the code, the function checks for the limits of the C int type.
- Issue #28544: Fix _asynciomodule.c on Windows. PyType_Ready() sets the reference to &PyType_Type. &PyType_Type address cannot be resolved at compilation time (not on Windows?).
- Issue #28082: Add basic unit tests on the new re enums.
- Issue #28691: Fix warn_invalid_escape_sequence(): handle correctly DeprecationWarning raised as an exception. First clear the current exception to replace the DeprecationWarning exception with a SyntaxError exception. Unit test written by Serhiy Storchaka.
- Issue #28023: Fix python-gdb.py on old GDB versions. Replace int(value.address)+offset with value.cast(unsigned char*)+offset. It seems like int(value.address) fails on old GDB versions.
- Issue #28765: _sre.compile() now checks the type of groupindex and indexgroup arguments. groupindex must a dictionary and indexgroup must be a tuple. Previously, indexgroup was a list. Use a tuple to reduce the memory usage.
- Issue #28782: Fix a bug in the implementation yield from (fix _PyGen_yf() function). Fix the test checking if the next instruction is YIELD_FROM. Regression introduced by the new "WordCode" bytecode (issue #26647). Fix reviewed by Serhiy Storchaka and Yury Selivanov.
- Issue #28792: Remove aliases from _bisect. Remove aliases from the C module. Always implement bisect() and insort() aliases in bisect.py. Remove also the # backward compatibility comment: there is no plan to deprecate nor remove these aliases. When keys are equal, it makes sense to use bisect.bisect() and bisect.insort().
- Fix a ResourceWarning in generate_opcode_h.py. Use a context manager to close the Python file. Replace also open() with tokenize.open() to handle coding cookie of Lib/opcode.py.
- Issue #28740: Add sys.getandroidapilevel() function: return the build time API version of Android as an integer. Function only available on Android. The availability of this function can be tested to check if Python is running on Android.
- Issue #28152: Fix -Wunreachable-code warnings on Clang.
- Don't declare dead code when the code is compiled with Clang.
- Replace C if() with precompiler #if to fix a warning on dead code when using Clang.
- Replace 0 with (0) to ignore a compiler warning about dead code on ((int)(SEM_VALUE_MAX) < 0): SEM_VALUE_MAX is not negative on Linux.
- Issue #28835: Fix a regression introduced in warnings.catch_warnings(): call warnings.showwarning() if it was overriden inside the context manager.
- Issue #28915: Replace int with Py_ssize_t in modsupport. Py_ssize_t type is better for indexes. The compiler might emit more efficient code for i++. Py_ssize_t is the type of a PyTuple index for example. Replace also int endchar with char endchar.
- Initialize variables to fix compiler warnings. Warnings seen on the "AMD64 Debian PGO 3.x" buildbot. Warnings are false positive, but variable initialization should not harm performances.
- Remove useless variable initialization. Don't initialize variables which are not used before they are assigned.
- Issue #28838: Cleanup abstract.h. Rewrite all comments to use the same style than other Python header files: comment functions before their declaration, no newline between the comment and the declaration. Reformat some comments, add newlines, to make them easier to read. Quote argument like 'arg' to mention an argument in a comment.
- Issue #28838: abstract.h: remove long outdated comment. The documentation of the Python C API is more complete and more up to date than this old comment. Removal suggested by Antoine Pitrou.
- python-gdb.py: catch gdb.error on gdb.selected_frame().
- Issue #28383: __hash__ documentation recommends naive XOR to combine, but this is suboptimal. Update the documentation to suggest to reuse the hash() function on a tuple, with an example.