
I'm writing an article series on Free Threading internals to learn more about Free Threading, explain how it works, and explain how it solved the "remove the GIL" issue where previous attempts failed.
- Reference counting (this article)
This first article explores the problem of tracking objects lifetime using reference counting in an efficient fashion.
We will see how the Gilectomy project (2016-2018) started with atomic operations and then switched to buffered reference counting, and how the nogil project (2021-2026) solved the performance issue using Biased Reference Counting.
Painting: The Bride by Marc Chagall (1950).
Python object reference count
Python C API relies on reference counting to track objects lifetime. When an object is created, its refcount is 1. Py_INCREF() increases the refcount and Py_DECREF() decreases the refcount. When the refcount reachs 0, the object is destroyed.
In C code, Py_INCREF() and Py_DECREF() are called very frequently, and so should be as efficient as possible.
An object reference count can be read with sys.getrefcount(obj).
Atomic operations
In 2016, the Gilectomy project was created by Larry Hastings to remove the GIL. To support calling Py_INCREF() and Py_DECREF() in parallel, Gilectomy started by using atomic operations on the object refcount. For example, Py_INCREF() calls the atomic function __sync_add_and_fetch():
typedef struct {
Py_ssize_t shared_refcnt;
} ob_refcnt_t;
typedef struct _object {
ob_refcnt_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
#define Py_INCREF(op) \
__sync_add_and_fetch(&op->ob_refcnt.shared_refcnt, 1)
The problem with the atomic operation is that it's a kind of locking and lock contention can cause bad performance. For example, if many threads modify the refcount of the same object, refcount operations will be serialiazed by the lock and so the code doesn't scale well with the number of threads.
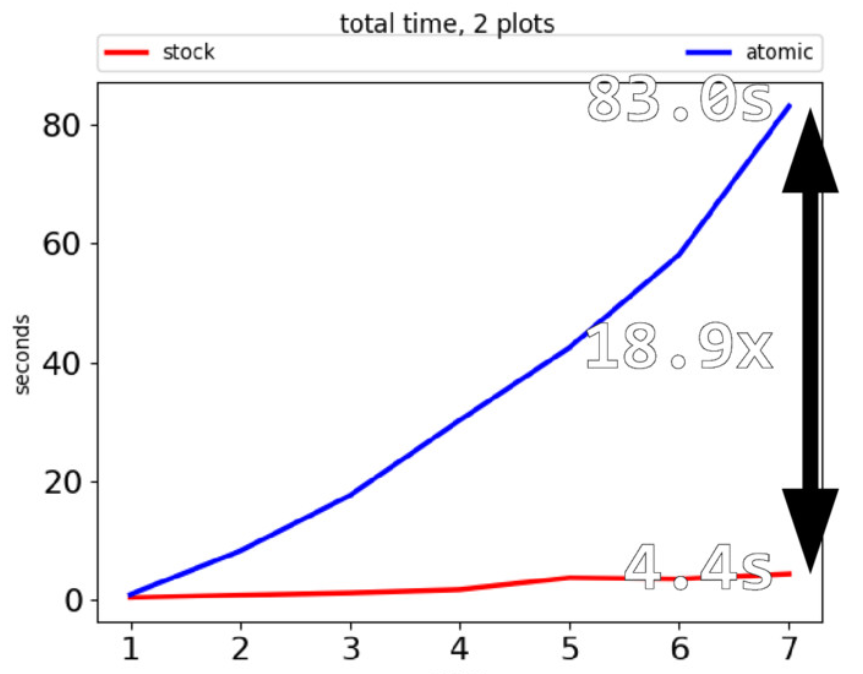
In June 2017, Larry Hastings measured (slides) that atomic refcount makes Python 18.9x slower on 7 CPU cores (4.4 seconds to 83.0 seconds):
CPython has multiple singletons objects which are commonly used and so can suffer from lock contention. Examples: None, integers in range [-5; 1024], empty string, single Latin-1 characters, etc.
In 2015, Christian Aichinger made an experiment to use atomic operations in Py_INCREF() and Py_DECREF(): it made Python 20% slower overall (on a single thread). Read the article: Python's GIL and atomic reference counting.
In 2020, the usage of atomic operations in Py_INCREF() was also discussed for sub-interpreters use case (see issue and PR). But at the end, it was decided to not share objects between sub-interpreters instead.
In 2007, using atomic operations in Py_INCREF() was already mentioned in a discussion about removing the GIL.
Gilectomy buffered reference counting
To make Gilectomy scale better, Py_INCREF() has been modified to use "buffered reference counting" instead. The Py_INCREF() function becomes:
static inline void Py_INCREF(PyObject *o)
{
PyRefLog *rl = PyThread_get_key_value(PyRefLogTLSKey);
if (PyRefPad_IsFull(rl)) {
PyRefLog_Rotate(rl);
}
PyRefPad_Write(rl->incref, o);
}
Py_DECREF() uses a separated reference log (rl->decref) to respect operations order.
In October 2016, Larry Hastings compared (slides) atomic refcount and buffered reference counting ("rcm") to a reference Python:
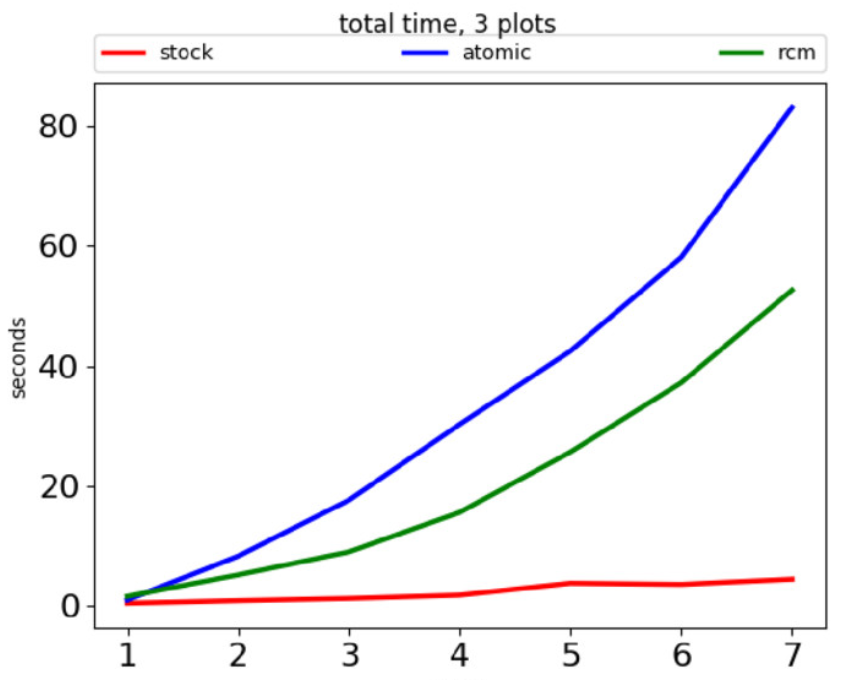
Performance is better on 7 CPU cores using "buffered reference counting", instead of atomic operations.
Read more about gilectomy:
- LWN: Progress on the Gilectomy (May 2017).
- Slides: gilectomy: how's it going? by Larry Hastings.
In 2018, using a tracing garbage collector and breaking the C API was considered: read LWN: A Gilectomy update. But it didn't happen in practice.
Biased Reference Counting
Creation of the nogil project
In 2021, Sam Gross created a "nogil" fork of CPython to remove the GIL. It uses "Biased Reference Counting" which is described in PEP 703:
It is based on the observation that most objects are only accessed by a single thread, even in multi-threaded programs. Each object is associated with an owning thread (the thread that created it). Reference counting operations from the owning thread use non-atomic instructions to modify a “local” reference count. Other threads use atomic instructions to modify a “shared” reference count. This design avoids many atomic read-modify-write operations that are expensive on contemporary processors.
Biased reference counting (BRC) is a technique first described in 2018 by Jiho Choi, Thomas Shull, and Josep Torrellas: article.
PyObject members before:
struct _object {
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
};
PyObject members after:
struct _object {
uintptr_t ob_tid;
uint32_t ob_ref_local;
Py_ssize_t ob_ref_shared;
PyTypeObject *ob_type;
};
The ob_refcnt is replaced with ob_ref_local and ob_ref_shared, and a new ob_tid member is added.
ob_ref_local is the "local" reference count, ob_ref_shared is the "shared" reference count, and ob_tid is the identifier of the thread which owns the object.
Creation of an object
Python calls PyObject_INIT(op) to create a new Python object. It initializes ob_ref_local to 1, ob_ref_shared to 0, and ob_tid to _Py_ThreadId().
_Py_ThreadId() gets the thread identifier. The function is called at each object creation, and at each Py_INCREF() and Py_DECREF() call. So it must be as efficient as possible. For example, on x86-64, it just has to read the fs CPU register:
static inline uintptr_t
_Py_ThreadId(void)
{
uintptr_t tid;
#if defined(_MSC_VER) && defined(_M_X64)
tid = __readgsqword(48);
#elif defined(__x86_64__)
__asm__("{movq %%fs:0, %0|mov %0, qword ptr fs:[0]}" : "=r" (tid)); // x86_64 Linux, BSD uses FS
#else
...
#endif
return tid;
}
Py_INCREF()
In Python 3.12, Py_INCREF() basically just has to increase the ob_refcnt member. It also checks if an object is immortal to implement PEP 683.
Python 3.12 code:
static inline void Py_INCREF(PyObject *op)
{
if (_Py_IsImmortal(op)) {
return;
}
op->ob_refcnt++;
}
In nogil, Py_INCREF() becomes more complex:
static inline int _Py_IsOwnedByCurrentThread(PyObject *ob)
{ return ob->ob_tid == _Py_ThreadId(); }
static inline void Py_INCREF(PyObject *op)
{
uint32_t local = _Py_atomic_load_uint32_relaxed(&op->ob_ref_local);
uint32_t new_local = local + 1;
if (new_local == 0) {
// local is equal to _Py_IMMORTAL_REFCNT_LOCAL: do nothing
return;
}
if (_Py_IsOwnedByCurrentThread(op)) {
_Py_atomic_store_uint32_relaxed(&op->ob_ref_local, new_local);
}
else {
_Py_atomic_add_ssize(&op->ob_ref_shared, (1 << _Py_REF_SHARED_SHIFT));
}
}
Fast path
If the object is owned by the current thread and is mortal, which is the common case, the code is basically:
uint32_t local = _Py_atomic_load_uint32_relaxed(&op->ob_ref_local);
uint32_t new_local = local + 1;
_Py_atomic_store_uint32_relaxed(&op->ob_ref_local, new_local);
The "relaxed" operations are cheap since there are no synchronization or ordering constraints imposed on other reads or writes, only these operations' atomicity is guaranteed.
Slow path
If the object is not owned by the current thread, a slower code path is used:
_Py_atomic_add_ssize(&op->ob_ref_shared, (1 << _Py_REF_SHARED_SHIFT));
where _Py_atomic_add_ssize() uses the "sequentially consistent" order which is slower than "relaxed" since it implies locking.
See Include/cpython/pyatomic.h header for more information on atomic functions used by CPython and memory order.
Py_DECREF()
In Python 3.12, Py_DECREF() basically decrements ob_refcnt and calls _Py_Dealloc(op) if the refcount is 0. It also checks if the object is immortal to do nothing in this case.
Python 3.12 code:
static inline void Py_DECREF(PyObject *op)
{
if (_Py_IsImmortal(op)) {
return;
}
if (--op->ob_refcnt == 0) {
_Py_Dealloc(op);
}
}
In nogil, the function becomes more complex:
static inline void Py_DECREF(PyObject *op)
{
uint32_t local = _Py_atomic_load_uint32_relaxed(&op->ob_ref_local);
if (local == _Py_IMMORTAL_REFCNT_LOCAL) {
return;
}
if (_Py_IsOwnedByCurrentThread(op)) {
local--;
_Py_atomic_store_uint32_relaxed(&op->ob_ref_local, local);
if (local == 0) {
_Py_MergeZeroLocalRefcount(op);
}
}
else {
_Py_DecRefShared(op);
}
}
Same as Py_INCREF(), cheap "relaxed" functions are used if the object is owned by the current thread. If the local reference count reachs 0, call _Py_MergeZeroLocalRefcount() (described below).
Otherwise, call slower _Py_DecRefShared() code path (described below).
Note: If the object is immortal, do nothing.
_Py_MergeZeroLocalRefcount() function
In Py_DECREF(), if an object is owned by the current thread and its refcount reached 0, _Py_MergeZeroLocalRefcount() is called.
void
_Py_MergeZeroLocalRefcount(PyObject *op)
{
assert(op->ob_ref_local == 0);
Py_ssize_t shared = _Py_atomic_load_ssize_acquire(&op->ob_ref_shared);
if (shared == 0) {
_Py_Dealloc(op);
return;
}
_Py_atomic_store_uintptr_relaxed(&op->ob_tid, 0);
Py_ssize_t new_shared;
do {
new_shared = (shared & ~_Py_REF_SHARED_FLAG_MASK) | _Py_REF_MERGED;
} while (!_Py_atomic_compare_exchange_ssize(&op->ob_ref_shared,
&shared, new_shared));
if (new_shared == _Py_REF_MERGED) {
_Py_Dealloc(op);
}
}
If the shared reference count is 0, the function just calls _Py_Dealloc(op).
Otherwise, it sets ob_tid to _Py_UNOWNED_TID (0), and then adds the flag _Py_REF_MERGED to shared reference count. If other threads called Py_DECREF() in parallel and the shared reference count became 0 in the meanwhile, _Py_Dealloc(op) is called. Otherwise, there are still shared references to the object and so it's still alive. The object will be destroyed once the shared reference count reachs 0.
Conclusion
Biased Reference Counting is more efficient than atomic operatons on the refcount because they use cheap "relaxed" operations on the refcount if the object is owned by the current thread which is the most common case.
In exchange, Py_INCREF() and Py_DECREF() functions became (way) more complex to implement Biased Reference Counting.